Building a Sentiment Analysis Tool for Gathering Audience Insights
When working with large volumes of qualitative data, whether from interviews, surveys, internal feedback, or public channels, it can be difficult to identify what users are actually saying. There is often a lot of valuable information buried in these responses, but not always a fast or reliable way to extract useful audience insights.
Sentiment analysis tools have become more accessible over the past few years, and as I looked into how they worked, I realized that building one tailored to my own workflow was surprisingly achievable. If you're interested in doing something similar, below is an overview of how it works and what it can help uncover.
Surfacing Audience Insight
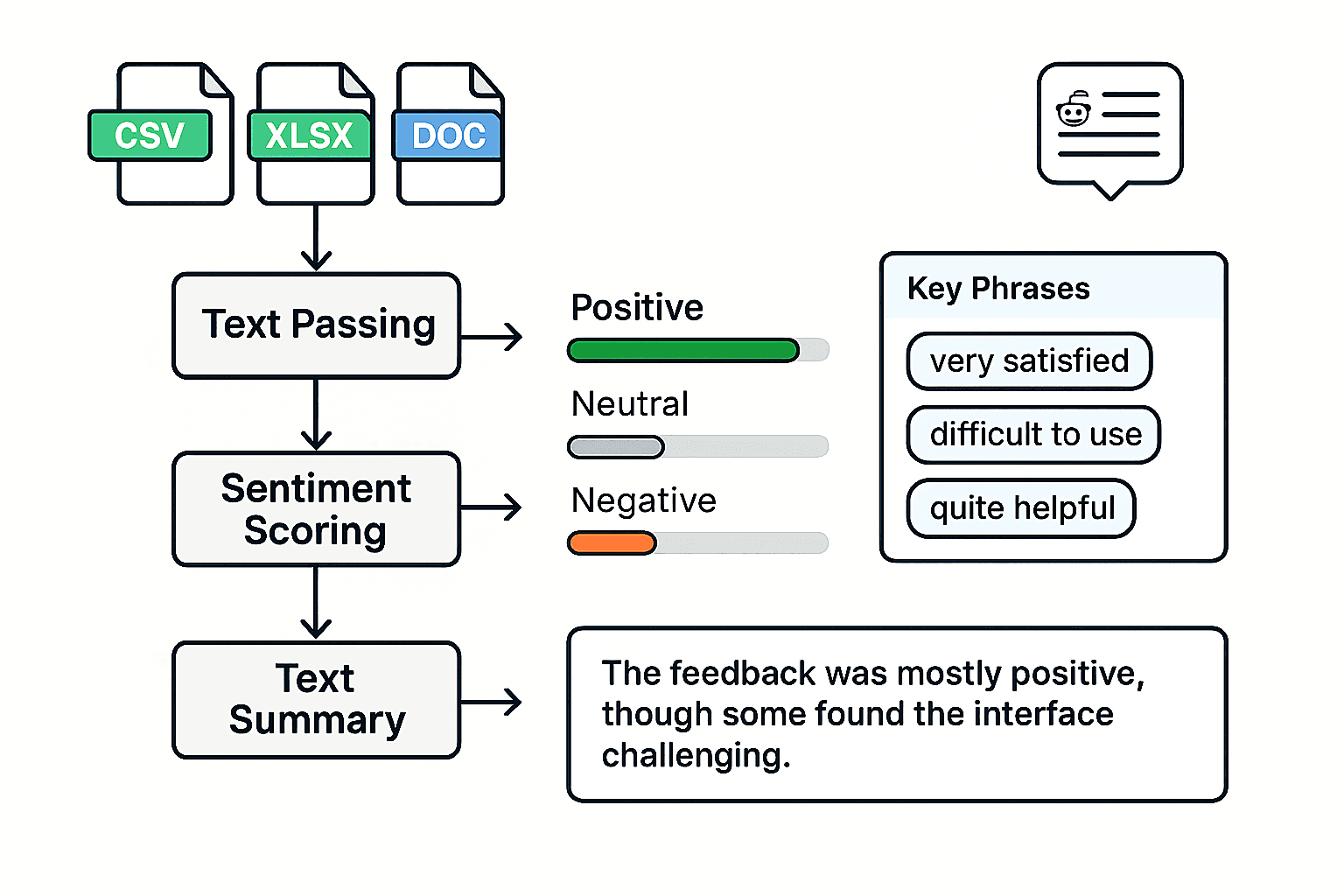
The sentiment analysis tool I built performs two core tasks. First, it analyzes uploaded text, such as interview transcripts, survey responses, or product reviews, and returns a breakdown of sentiment, emotional tone, and repeated phrases. Second, it allows a user to ask about a topic and retrieves recent public content from social media sites such as Reddit, then summarizes how people are discussing that topic and what kinds of responses are showing up. The result is a snapshot of both internal and external audience insights.
For example, when doing user research, you might collect dozens of open-ended survey responses and social media posts. Instead of tagging each one by hand, the tool highlights common praise such as “easy to use” and complaints like “hard to get started,” while summarizing the overall tone in a few clear sentences. It makes the process of understanding feedback faster, more structured, and easier to communicate to others.
How It Works
The tool is composed of a set of focused components, each performing a specific task. I built mine using Python, but other programming languages would work just as well. Everything is connected using an API layer. In this case, I used FastAPI to manage how the parts communicate with one another.
- Uploaded files like CSV, Excel, or Word documents are parsed using file handling libraries. These are converted into plain text to prepare for analysis.
- A basic natural language processing library scores each line or paragraph based on polarity. This generates a count of how much of the feedback is positive, neutral, or negative.
- The full dataset is sent to a language model using a custom prompt. It returns short phrases that reflect positive or negative sentiment. These are grouped and returned in a consistent format.
- A second prompt asks the model to write a short summary that captures the emotional tone and common themes.
- For external topics, the app scrapes recent Reddit posts based on a keyword, then runs that content through the same pipeline.
The app uses a mix of traditional language processing techniques and a large language model (LLM). Python handles the parsing and sentiment scoring, but the prompts guide the model in interpreting tone, surfacing patterns, and generating summaries that are accurate and easy to act on. The scoring step is rule-based, while the interpretation, including phrase extraction and summarization, relies on the model.
I used Mistral, a free and open-source model running locally through Ollama. Other open-source models like LLaMA 3, Falcon, or Gemma would work just as well, and commercial options like GPT-4, Claude, Cohere, or Gemini are also compatible depending on the setup.
Easier to Build Than You Might Expect
If you are considering creating something like this, you may find it more approachable than it first appears. With a few well-defined components, such as text parsing, sentiment scoring, phrase extraction, and summarization, you can build a lightweight tool that turns qualitative input into usable audience insights. It provides a structured way to understand how people are reacting, what they care about, and where common challenges appear.
This kind of tool is flexible and can be extended to include other data sources, connect to internal dashboards, or be adapted for different teams and workflows. It is a simple and effective way to uncover meaning in unstructured human feedback.